This is part two in a series about creating my own email marketing infrastructure. Last week we talked about how I got started with my email marketing. Click here to read that if you haven’t already. I found a collection of businesses I could contact, got it saved locally so I can work with it, and analyzed all of the websites in a small area around me so that I could prioritize who to contact first.
This week, we’re going to talk a little more about the methods I used to construct the marketing emails. In my experience, email marketing is a fickle experience with lots of places to get into trouble. Where it’s easiest to get into trouble before you start is the server side. See, email isn’t just a communication between two individuals, it’s a communication between two individuals via two or more computers, each with its own rules about what is and isn’t allowed.
Spam is the problem. Spam has been the problem since the advent of email and email marketing. Obviously, our marketing can’t be effective if it is categorized as Spam, to avoid that we have to understand the common ways servers identify Spam:
- Image to Text Ratio
- Number of external links
- Attachments & Size
- Volume
- Content of the text
Image to Text Ratio
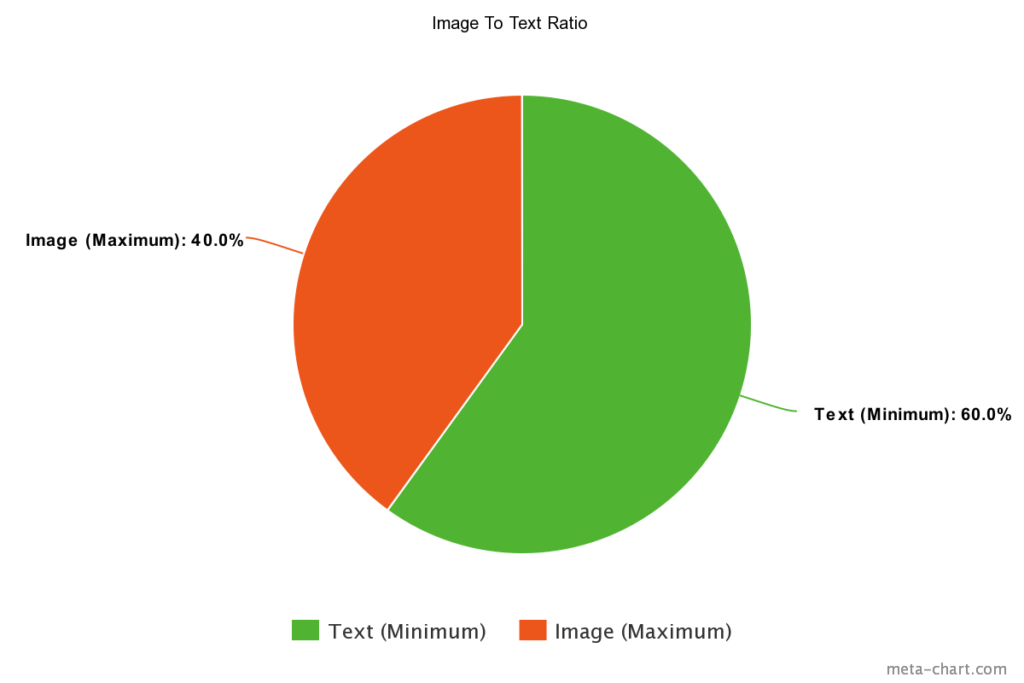
This percentage is a visual rule, so use this when creating your layouts. And whatever you do, never bake the text portion of your email into the images. This will make it harder to deliver your email, and make it harder for users with disabilities to engage with your marketing.
This is one that is a lot more common now than it used to be, and I’ve seen it throw several businesses for a loop. I absolutely understand where they’re coming from. An email that has striking images and pops with color and style is much more likely to stand out from the rest of a user’s inbox, and marketing often boils down to trying to stand apart from the pack.
But the issue is that not everyone that uses email is doing it just for communication or marketing. There’s a whole world of malicious email out there, and one of the tactics they’ve been using in the last few years is sending their messages as images so that the content of the email can’t be scanned for common Spam patterns. Since it takes a lot of computing power to analyze the text in images, server administrators frequently rely on a ratio of images to text to determine if an email is likely to be Spam.
This means you have to be very careful about the number of images you include in your email so that you’re not likely to set off the rules in place to protect users from phishing and other social engineering scams likely to use these tactics.
Number of external links
The purpose of Spam is usually to get a user to perform an action of some kind. Spam emails and marketing emails are not so different in this. In most cases, this is done on an external website so that there is less evidence of what is happening on the email server. To accomplish this, many spam emails are just littered with links in an effort to get the user to click on even one of them and be transported off to where the spammer has full control.
To make it even more complicated, the number of images can also count towards setting off this rule as they all count as requests to a remote (and therefore suspect) server.
The best way to approach this is to insure that your email has a clear singular call to action. A single thing the email itself is asking the user to do. Usually this will involve clicking a link to be directed to your website to get more information about something. If there are any other links in the email, they should direct to the same website if possible, and be kept to a minimum. The rule I try to keep to is no more than 4 links per email. That way any additional requests can be used for images, but as mentioned above these should also be limited to only a few.
Attachments & Size
Attachments are an important part of the email protocol. They are extremely useful for getting files between people over a distance. For this reason server administrators won’t outright ban attachments, but since they are also the primary way that viruses are spread through email the rules they do put into place can be pretty draconian.
My advice, avoid using attachments entirely if you can. And never send an email with an attachment as your first point of contact with someone. It very likely won’t go through. If you do have to send an attachment, try to stick to images and PDF files. Any file format native to Microsoft Office is frequently abused by malicious actors and some server administrators will outright block them, with good reason.
Most emails these days are actually little different than full webpages. For this reason there can be a lot under the surface that the user never sees, and that means that things can be done to try to abuse that privilege. Server administrators are practical people, and rather than trying to keep up with all the new strategies, they just put a max cap on the filesize of the email to make this less viable.
For this reason, you should try to keep the size of your entire email, including remote images and attachments, less than 2MB. This also goes a long way towards making your email more friendly for mobile users who may not have strong network connectivity or limited data.
Volume
Spam campaigns are done in units of thousands and millions. Each individual email is very unlikely to get any takers, so spammers get around this on sheer automated volume. Server administrators have known this for decades, and set up networks of servers to keep track of email volume from servers across the world, and when one gets too large those networks will warn that there is a potential spammer and may recommend blocking all emails from that server until the problem is taken care of.
This is a bad situation for a server administrator to be in, because proving the problem is fixed can be difficult and time consuming, so a lot of servers enforce their own rate limiting protections and will shut down your account if you surpass those limits. Unless you’re using a service built for large scale email marketing, your best best is to limit yourself to only sending less than a hundred emails an hour, and significantly less than 750 emails a day. Keeping in mind that your email server may be more or less strict, but you can set off this rule on the servers you’re emailing as well as the one you’re emailing from.
Content of the text
Finally, you have to be very aware of what you are writing in your email. Spam has been around for decades, and a lot of servers and server administrators have been too. There are all sorts of phrases and words that will blacklist your email outright, and larger email providers are even using AI to analyze the text of your email and make judgment calls about how likely it is to be Spam.
Be clear and honest with your text. Trying to deceive someone or trick them into doing what you want will almost never convert to a sale anyway, and it greatly increases the risk that your email will never be read. Don’t ramble too much and confuse the reader with more information than they need. Choose a single subject and a single call to action for that email. You can break this rule a little with newsletters, but you should never send a newsletter to someone who hasn’t opted into receiving them.
Next week I’ll go into more detail about how I crafted my emails according to these rules, and the systems I built to help automate that process.
If you’d like to learn a little more about how to optimize your website, try my blog post on image formats.
And, if you can’t wait until next week to learn more about my approach to email marketing, or you’re interested in talking about any of the services I offer, fill out the form below to get in contact with me directly.